正文共:3399字 13圖
預計閱讀時間:9分鐘
最近,蘋果春季發布會結束之后,我們從發布會提取了一個關鍵詞:【M4】。
確切來說,是蘋果的M4芯片。
時隔六年,蘋果iPad Pro 終于升級了版本,并且憑借著僅 5.1 毫米的機身厚度,成功取代 iPod nano 成為史上最輕薄的蘋果設備。
作為此次蘋果全新重磅產品,新一代iPad Pro除了更輕薄,還搭載了首發蘋果自研M4芯片,讓CPU性能提高35%,GPU性能提升50%。
而這,也是引起業內外關注的重點。
關于[M4]算力的猜想
在對M4芯片展開暢想之前,我們先來看看市面上第一梯隊的芯片GPU算力如何?
驍龍730 1.84 TFLOPS
驍龍740 2.21 TFLOPS
驍龍750 3.15 TFLOPS
英偉達GTX 1650 2.98 TFLOPS
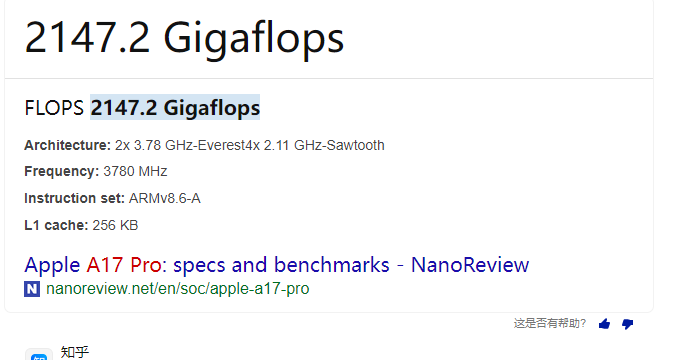
蘋果A17 Pro ≈ 2.15 TFLOPS

關于最新的M4芯片,據介紹其神經引擎具備 38 TOPS(Tera Operations Per Second,每秒萬億次運算)的運算能力。
38這個數值看起來似乎非常高,但這包含了GPU+CPU共同的運算能力,我們從A17 Pro和第一梯隊芯片數據可以預測得到,M4芯片的GPU運算能力并不會比同行們高出太多,甚至是持平的水平。
這樣一個算是沒有特別亮點的芯片發布,對蘋果而言,究竟意味著什么?
[M4]將會帶來什么?
在過去幾年里,面對不可忽視的AI大模型浪潮,蘋果卻在AI領域一直按兵不動,這引起了各方猜測:蘋果是否在憋一次大招?還是策略方向的決策失誤?
這些都暫且按下不表。
【M4】究竟會為蘋果帶來什么變化,或者說它將如何為蘋果一直以來的強項——用戶交互帶來什么顛覆性的用戶體驗?
(在十多年的發展中,蘋果主要是通過自主研發硬件和優化軟件的方式,來創建和控制自己的產品生態系統,這在過去取得了巨大成功。)
這里提出一個問題:大家覺得蘋果是否真的沒有對AI進行布局?
首先,是那個十多年前非常先進、如今已經被各家AI聊天工具甩下幾條街的Siri。
這是蘋果AI最初級的市場呈現,在【M4】背景下,我們大概能猜測,在 iOS 18中它會全面更換算法,用蘋果自己的大語言模型驅動Siri。
至于這個大語言模型的名字,我們從Ferret到MLLMs,再到上個月透漏出來的ReALM,它叫什么已經不是重點,我們暫且就認為它叫ReALM。

有更具體的消息表示,它有80M、250M、1B和3B四個版本的大小,其中哪怕最小的80M模型都已經比GPT-4的表現更好,而這個尺寸的模型是可以直接裝進運存的,最大的3B模型的表現更是超過GPT-4一大截。
80M版本的模型大概率會內置在本地,用來處理屏幕實體內容。舉例來說,當前你要AI工具幫你處理什么或者識別什么,你至少要把你看到或者要描述的東西用圖片或文字,單獨發給AI的輸入界面。
比如,一張圖片里出現了奇怪的東西,你不知道這個東西是干什么用的,你要先截圖,然后把截下來的圖片發給AI,問它,這個東西是干什么的呀?于是這個步驟就涉及到很讓人頭疼的隱私問題,其次就是不方便。
相當多60歲以上的手機用戶不知道怎么做屏幕截圖,或者要求再高一點,不知道怎么截取圖像中的一部分,但ReALM對屏幕實體的識別功能就能大幅改進以上兩個弱點。
由于隱私和使用體驗這兩個關鍵點,外界猜測蘋果將會把ReALM放在本地運行。
畢竟在過去,“隱私”這一核心價值觀的設立,對蘋果而言是一塊金字招牌。
RECRUIT
在2017年的WWDC大會上,蘋果宣布采用聯邦學習(Federated Learning)技術來改進Siri的語音識別功能,因為它解決了隱私安全和訓練大模型之間的沖突。
它可以在設備上進行識別,而不需要將用戶的語音數據上傳到云端進行處理,從而保護用戶的隱私。
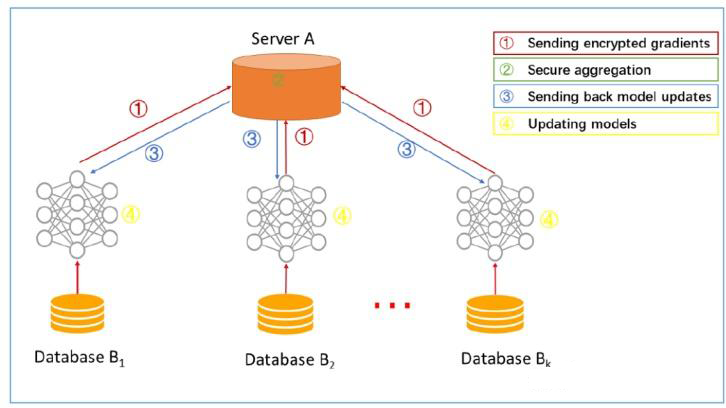
當初始化的模型,在本地完成訓練后,傳回云端的只是一個基于本地數據訓練而得到的模型,而不是用戶數據本身。
這些本地模型被傳輸回云端后,通過模型聚合的方式,用戶所有的本地模型將合并成一個全局模型。
最后,蘋果會通過模型更新的方式,將合并后的全局模型傳輸回用戶的本地設備上,替換原有的模型。
如此一來,蘋果既實現了模型的訓練,又保護了用戶的隱私安全,可謂一舉兩得。
要想在本地運行這樣一個龐大的模型,并不是一件簡單的事情,因為需要占用海量的內存。
GPT-4表現搶眼,但它們都是在云端運行的,我們的手機或PC端只是發出問題和接收答案,所有的計算都由OpenAI的服務器群組搞定。
上億人的使用,推理計算量是非常恐怖的,于是就會開始遇到ChatGPT無響應、輸出慢、被黑客攻擊和大家最擔心的隱私等等問題。
(有趣的是,在和同事討論這個暢想的時候,他們確實會第一時間考慮到關于隱私方面的隱患。)

我們可以最保守地、最粗糙地按照每10億參數占用1GB內存去換算,那么2000億參數就需要200GB內存,然后為了保證其他軟件的順利運行,還需要額外多準備出十幾GB的內存,于是能運行ReALM大語言模型的蘋果手機可能需要配210GB內存。可今天最頂級的iPhone15 Pro Max是多少內存呢?8GB。
要運行多模態大語言模型,需要把內存加大26倍才可以,這是不可能的,今天就算是安卓陣營的手機,最高內存也只有32GB,離210GB還遠得很。
但蘋果還是打算把這個模型放在本地運行,方法是使用閃存。通俗地說,就是iPhone存放照片和安裝App的那部分閃存空間。

通常來說,這么做速度上會慢15-50倍,你可以想象一下,大約1-2秒鐘才蹦出下一個字,一段300字的答案你要等7-10分鐘才能完整顯現出來。
但蘋果所做的突破正在于此——大幅優化閃存中大語言模型的運行速度。具體方法就是,在大模型運行過程中,只保留一開始就激活的神經元,后續每次運算都基于前一次參數的激活狀態進行刪除和添加。蘋果把這個技術起名為滑窗(sliding window)。此外,還有優化傳輸的一些操作。(來自蘋果的研發人員發布的論文,這些研究有些可能是未來幾個月后會應用在產品中的,也有一些只是可行性上的嘗試,不一定會用在未來產品上。)

△ 蘋果公司關于其在多模態大模型的研究論文。
這樣做是否可行呢?它可能需要一個前提,就是大語言模型在處理前后兩個token的時候,神經元激活的狀況是否高度相似。
而蘋果的優勢還不止于此。因為iPhone、iPad、MacBook這些硬件里的處理器,不論是A17還是M3,都早早留出了很多神經網絡專用的算力。
比如,對iPhone來說,其實從2017年就開始首次在iPhoneX的A11處理器中內置了神經引擎。
至于蘋果是怎么做到只用比GPT-4少得多的參數量就能達到很好的性能,那只有等到今年6月10日WWDC2024發布會上才能最終揭曉。
[M4]將會帶來什么?
總結來說,就是【M4】背景下帶來的下一代操作系統ios 18,可能是蘋果全面開啟AI時代的開始。
試想一下 ,如果嵌入到iPhone中的,是一個能夠在本地部署,并且高度優化過后的 Siri ,將會讓手機成為一個幾乎無所不包的多模態工具,無論是寫文章、編程,還是繪畫,都能隨時隨地,在小小的屏幕間實現。
更重要的是,這將讓AI調度中樞內置到蘋果的生態系統里,實現用戶使用的平權。
所謂的“平權”,就是不論年齡、不論職業、不論學歷、不論學時、不論性別等,擺脫各種人群標簽限制,每個人在使用蘋果的產品時,都不會有功能的差距。
也就是解決“有人不會操作和不懂功能”的問題,再也不會有人把智能產品用成初始老人機的效果,因為這一切都由Siri這樣的“助理”幫你解決了。
也許未來的某天中午,到了飯點,Siri可以根據你上午看了好幾遍炸雞廣告,分析出你想吃炸雞,并為你選擇附近3公里內評分最高的那家直接下單,而你全程不需要參與。
或者在你第二天有行程的時候,Siri會根據你的行程,幫你設置鬧鐘,安排出行時間,列出行李清單,甚至計算每個步驟所需要的時間,然后在合適的時候打開手機里的叫車軟件,幫你約一輛網約車,而網約車還是根據你日常叫車習慣給你安排的車型。
至少,這真的太適合經常要給家里老母親視頻教學電子產品用法的我了。
2011年,蘋果用一句“Hey,Siri”,讓世界第一次感受到了AI的魅力。
2024年,蘋果用一個【M4】,又讓人們開始對蘋果翹首以待。
— END —
資料來源 | 知乎嘉賓商學、知乎阿爾法工廠、得道卓克科技參考、知乎無錫軟件資訊發布、網易號 DeepTech深科技





 粵公網安備 44030502007885號
粵公網安備 44030502007885號